More details
Why this project?
Since childhood, I'm passionate about video games. Mario games are a classic and timeless reference. I will never stop to be amazed by the quality of level design that is involved. Over the years, I was also quite disappointed about the behavior of bots that you can see when playing with or against. It was like their behavior were hardcoded in some way and didn't feel human at all.
Then, some events catch my attention:
- In 1997, an IBM supercomputer called Deep Blue won a six-game chess match versus the world chess champion Garry Kasparov,
- In 2015, Google DeepMind's AlphaGo program defeated the European Go champion Fan Hui and top-ranked Lee Sedol in 2016,
- April 13, 2019, OpenAI Five, the Dota 2 AI developed by OpenAI wins back-to-back games versus Dota 2 world champions OG at Finals, becoming the first AI to beat the world champions in an esports game. I remember me saying to a friend that there is no way an AI can beat human at this game since it requires teamwork and collaboration. I was indeed wrong and deeply interested but who could have thought that you could train an AI against itself for 10 000 years of games?
While Deep Blue used brute computational force to evaluate millions of positions, the others rely on neural netwoks and reinforcement learning. In the end, I discovered that OpenAI team released Gym, an open source Python library for developing and comparing reinforcement learning algorithms. I decided to play with it and specially with Mario games. Thankfully, a Gym environment for Super Mario Bros. is available for me to use.
I strongly believe reinforcement learning should get more interest because the field of applications are yet under estimated. I think it could be a good tool to run experiences that could have been limited by human constraints (time, money, risk?) but also for discovering bug or glitch (e.g. physic engine exploit or bug discovery).
What is this project for?
This project is a playground for me to apply ML and RL algorithms on my preferred victim named Mario! And since we can exceed human time capacity with RL, I wanted to know in what way Reinforcement Learning from scratch could be better than Machine Learning (as complex as it can be) on human generated data. Of course, keeping in mind that RL is more suited for the task of playing video games.
How does it work in a nutshell?
Gym is an open source Python library for developing and comparing reinforcement learning algorithms by providing a standard API to communicate between learning algorithms and environments, as well as a standard set of environments compliant with that API.
In a RL framework, there is 5 elements that are relevant to know:
| agent |  |
| actions |  |
| environment |  |
| reward | A value returned by the environement and given to the agent based on the action performed in the environment. |
| policy | A strategy to determine the next action based on the (state-action-reward). This is basically the core of a RL algorithm. |
Agent acts with certain actions which transform the state of the agent, each action is associated with reward value produced by the environment. The next action is returned by the policy that determines the best action for the agent given the current state, the current reward and the expected reward. Roughly speaking, a policy is an agent's way of behaving at a given time. Now, policies can be deterministic and stochastic, but finding an optimal policy is at the core of a RL project and building new policy system falls in the field of RL research.
Given the next action by the policy and the current state, the environment proceed to a .step() and returned the reward and the new state. And so on...
The main difficulty remains the Q-learning aspect of a policy. The Q-learning is a function that computes the potential reward given a particular action at a given state. However, it would be too simple, different actions in different states will have different associated reward values. When the environment becomes too complex, neural nets are used to compute the Q-learning. This is what is called Deep RL.
Below is a simplified view of a RL process:
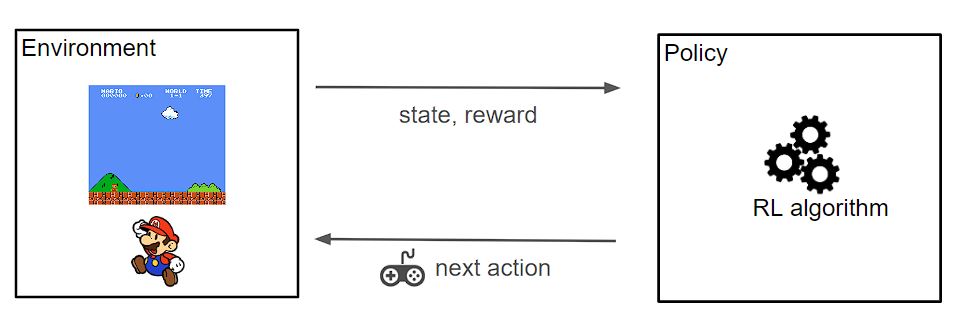
The policy we use in this project is the Proximal Policy Optimization developed by OpenAI which claims to perform comparably or better than state-of-the-art approaches while being much simpler to implement and tune. PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance.
Below is an overview of the main scripts developed in the python project and how do they fit together:
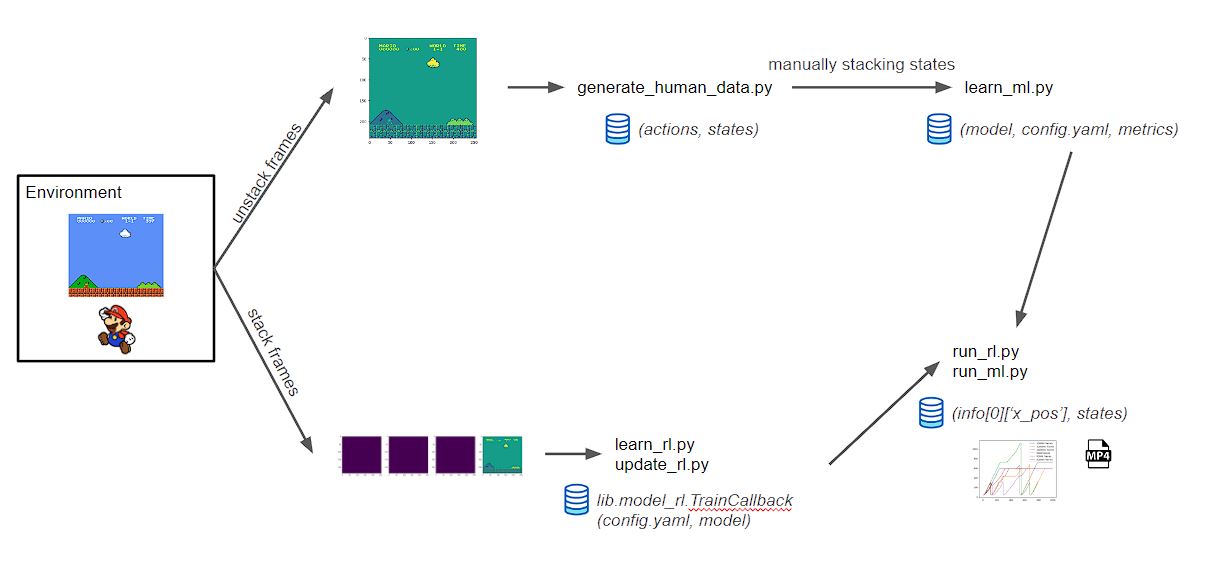
Improvement/Extension
My dear friend Mario, I will enlight you with my recommendations, cheers!

- you could use some computer vision and specifically some object detection to know what to do in specific situation (like jumping when facing a Koopa),
- you could play with the different parameters (stack, learning rate ...) and test other policies and others neural network architectures,
- to be fair, both algorithms RL and ML should be compared on a new level,
- you should store models in a model registry and data and metadata in a proper database,
- your project need some testing and you should implement test data with unit test ASAP.
- the Q-learning could be speed up with CUDA,
- maybe you could have less scripts by using abstract classes and a factory pattern, try it out!